


Figure AI released research around its Helix vision-language-action model as it tests its humanoids for logistics tasks.
The post Figure AI studies Helix model, preps humanoids for logistics appeared first on The Robot Report.

Figure is building the Helix model and a data engine to enable a fleet of humanoid robots to learn logistics tasks. Source: Figure AI
Figure AI Inc. this week introduced a real-world application for its humanoid robots and Helix model: package manipulation for triage in logistics.
“This task demands human-level speed, precision, and adaptability, pushing the boundaries of pixels-to-actions learned manipulation,” said the Sunnyvale, Calif.-based company.
At the core of this application is Helix, Figure’s internally designed vision-language-action (VLA) model. Announced just last week, this model unifies perception, language understanding, and learned control.
Humanoid addresses logistics use case
This task presents several key challenges, noted Figure AI. Packages come in a wide variety of sizes, shapes, weights, and rigidity – from rigid boxes to deformable bags, making them difficult to replicate in simulation.
The Figure 02 humanoid robot must determine the optimal moment and method for grasping the moving object and reorienting each package to expose the label. Furthermore, it needs to track the dynamic flow of numerous packages on a continuously moving conveyor and maintain a high throughput.
Since the environment can never be fully predictable, the system must be able to self-correct. Addressing these challenges isn’t only a key application of Figure’s business; it also yielded generic new improvements to Helix System 1 that all other use cases now benefit from, the company said.
Helix visual representation improves
Figure AI claimed that its system now has a rich 3D understanding of its environment, enabling more precise depth-aware motion. While its previous System 1 relied on monocular visual input, the new System 1 uses a stereo vision backbone coupled with a multiscale feature extraction network to capture rich spatial hierarchies.
Rather than feeding image feature tokens from each camera independently, features from both cameras are merged in a multiscale stereo network before being tokenized, explained the company. This keeps the overall number of visual tokens fed to Figure’s cross-attention transformer constant and avoids computational overhead.
The multiscale features allow the system to interpret fine details as well as broader contextual cues, which together contributing to more reliable control from vision, Figure said.

Register today to save 40% on conference passes!
Preparing for deployments at scale
Deploying a single policy on many robots requires addressing distribution shifts in the observation and action spaces due to small individual robot hardware variations. These include sensor-calibration differences (affecting input observations) and joint response characteristics (affecting action execution), which can impact policy performance if not properly compensated for, said Figure AI.
Especially with a high-dimensional, whole-upper-body action space, traditional manual robot calibration doesn’t scale over a fleet of robots. Instead, Figure trains a visual proprioception model to estimate the 6D poses of end effectors entirely from each robot’s onboard visual input.
This online “self-calibration” allows strong cross-robot policy transfer with minimal downtime, the company said.
By using the learned calibration and visual proprioception module, Figure was able to apply the same policy, initially trained on a single robot’s data, to multiple additional robots. Despite variations in sensor calibration and small hardware differences, the system maintained a comparable level of manipulation performance across all platforms, it asserted.
Figure said this consistency demonstrated the effectiveness of learned calibration in mitigating covariate shifts, effectively reducing the need for tedious per-robot recalibration and making large-scale deployment more practical.
Data curation and speeding up manipulation
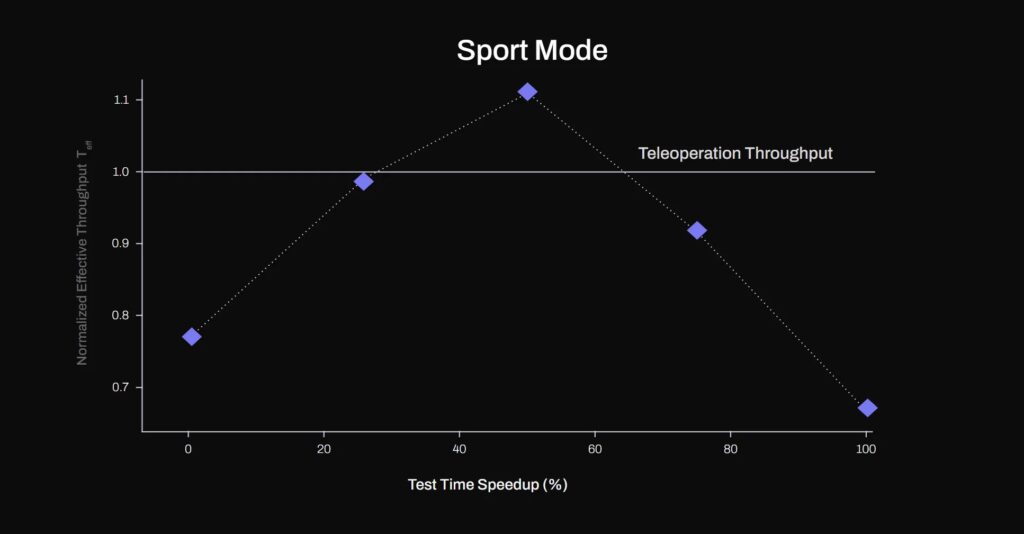 Test time speed up via action chunk re-sampling. With a 50% test time speed up, S1 achieves higher effective throughput than demonstration data (T_eff>1). | Source: Figure AI
Test time speed up via action chunk re-sampling. With a 50% test time speed up, S1 achieves higher effective throughput than demonstration data (T_eff>1). | Source: Figure AIOn the data side, Figure said it took particular care in filtering human demonstrations, excluding the slower, missed, or failed ones. However, it deliberately kept demonstrations that naturally included corrective behavior when the failure that prompted the correction was deemed due to environmental stochasticity rather than operator error.
Working closely with teleoperators to refine and uniformize manipulation strategies also resulted in significant improvements, the company said.
In addition to uniformizing manipulation strategies, Figure has also worked to eventually go beyond human manipulation speed.
It applied a simple test-time technique that yielded faster-than-demonstrator learned behavior. Figure interpolated the policy action chunk output, which called “Sport Mode.” Its System 1 policies output action “chunks,” representing a series of robot actions at 200hz.
For instance, the company said it can achieve a 20% test-time speedup, without any modifications to the training procedure, by linearly re-sampling an action chunk of [T x action_dim]—representing an T-millisecond trajectory—to a shorter [0.8 * T x action_dim] trajectory, then executing the shorter chunk at the original 200 Hz control rate.
Speeding up the policy execution via linear re-sampling or “sport mode” was effective up to a 50% speed up, the company said. This is likely rendered possible by the high temporal resolution (200Hz) of the action outputs chunks.
However, when going beyond 50% speed up, the effective throughput started to drop substantially as motions become too imprecise, and the system needed to be reset frequently, reported Figure. The company found that with a 50% speed increase, the policy achieved faster object handling compared with the expert trajectories it is trained on ( T_eff>1).
Figure AI shares Helix results so far
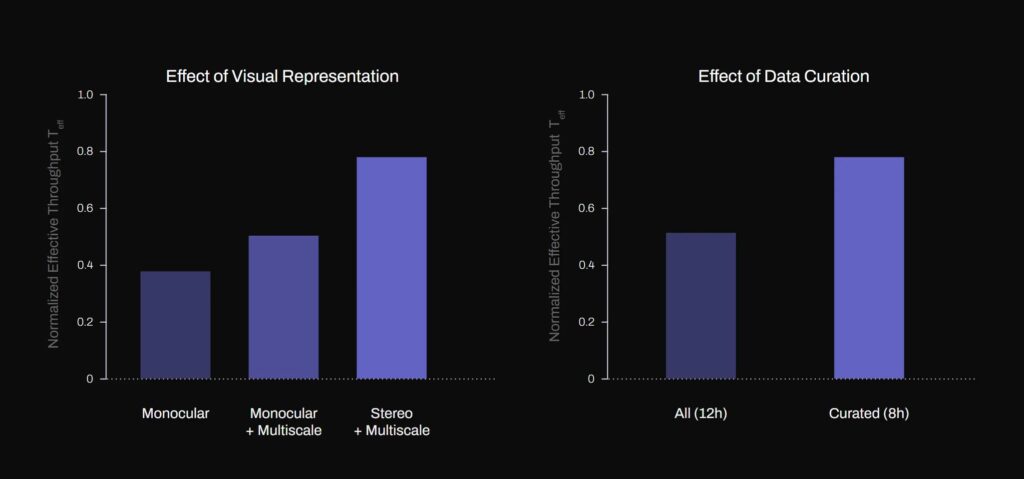
Figure measured the system’s performance using the normalized effective throughput T_eff, which represents how fast packages are handled compared with the demonstration data it is trained on. This takes into account any time spent resetting the system if necessary.

As an example, T_eff > 1.1 represents a manipulation speed 10% faster than the expert trajectory collected for training. Figure AI said it found that both the multiscale feature extraction and implicit stereo input could significantly improve system performance.
The company also noted the improved robustness to various package sizes when adding stereo. The stereo model achieves a 60% increase in throughput over non-stereo baselines.
In addition, Figure found that the stereo-equipped S1 can generalize to flat envelopes that the system was never trained on.
The company also found that for a single use case, data quality and consistency mattered much more than data quantity. Its results showed that a model trained with curated, high-quality demonstrations achieved 40% better throughput despite being trained with one-third less data.
Figure AI concluded that it has found how a high-quality dataset, combined with architectural refinements such as stereo multiscale vision, online calibration, and a test-time speed up, can achieve faster-than-demonstrator dexterous robotic manipulation in a real-world logistics triaging scenario.
Its system did this all while using relatively modest amounts of demonstration data, said the company. Figure said Helix shows the potential for scaling end-to-end visuo-motor policies to complex industrial applications where speed and precision are important.
The post Figure AI studies Helix model, preps humanoids for logistics appeared first on The Robot Report.