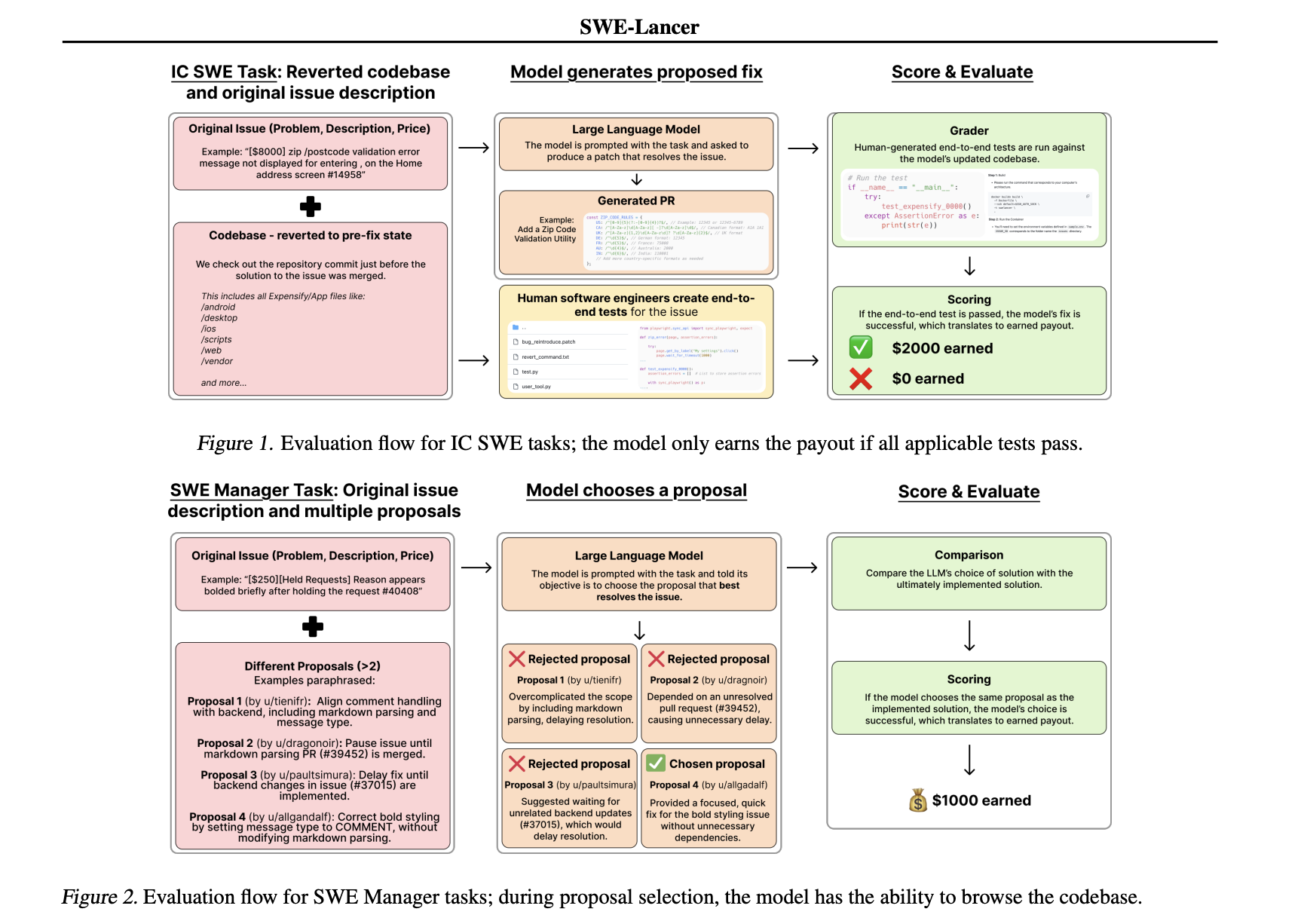
Addressing the evolving challenges in software engineering starts with recognizing that traditional benchmarks often fall short. Real-world freelance software engineering is complex, involving much more than isolated coding tasks. Freelance engineers work on entire codebases, integrate diverse systems, and manage intricate client requirements. Conventional evaluation methods, which typically emphasize unit tests, miss critical aspects such as full-stack performance and the real monetary impact of solutions. This gap between synthetic testing and practical application has driven the need for more realistic evaluation methods. OpenAI introduces SWE-Lancer, a benchmark for evaluating model performance on real-world freelance software engineering work. The benchmark is Read More
Addressing the evolving challenges in software engineering starts with recognizing that traditional benchmarks often fall short. Real-world freelance software engineering is complex, involving much more than isolated coding tasks. Freelance engineers work on entire codebases, integrate diverse systems, and manage intricate client requirements. Conventional evaluation methods, which typically emphasize unit tests, miss critical aspects such as full-stack performance and the real monetary impact of solutions. This gap between synthetic testing and practical application has driven the need for more realistic evaluation methods. OpenAI introduces SWE-Lancer, a benchmark for evaluating model performance on real-world freelance software engineering work. The benchmark is
Addressing the evolving challenges in software engineering starts with recognizing that traditional benchmarks often fall short. Real-world freelance software engineering is complex, involving much more than isolated coding tasks. Freelance engineers work on entire codebases, integrate diverse systems, and manage intricate client requirements. Conventional evaluation methods, which typically emphasize unit tests, miss critical aspects such as full-stack performance and the real monetary impact of solutions. This gap between synthetic testing and practical application has driven the need for more realistic evaluation methods. OpenAI introduces SWE-Lancer, a benchmark for evaluating model performance on real-world freelance software engineering work. The benchmark is
FIXEDD began as a personal website with a focus on construction topics. As it evolves, FIXEDD aims to become a valuable resource for AEC professionals, providing current industry news, software updates, and expert advice. With a vision to grow and make an impact.
FIXEDD began as a personal website with a focus on construction topics. As it evolves, FIXEDD aims to become a valuable resource for AEC professionals, providing current industry news, software updates, and expert advice. With a vision to grow and make an impact.