

2023 was the year when the potential and complexity of Large Language Models (LLMs) were growing rapidly. Looking at the open source and research advancements in 2024, it seems we are going to a welcome phase of making models better (and smaller) without increasing their size.
In this month’s article, I am highlighting four recent papers consistent with this theme:
1. Weight averaging and model merging allow us to combine multiple LLMs into a single, better one without the typical drawbacks of traditional ensembles, such as increased resource requirements.
2. Proxy-tuning to boost the performance of an existing large LLM, using two small LLMs, without changing the large model’s weights.
3. Creating mixture-of-experts models by combining multiple smaller modules results in LLMs that compete with and often surpass their larger counterparts in efficiency and effectiveness.
4. Pretraining a small 1.1B parameter LLM reduces development and operational costs and opens new avenues for educational and research applications.
1. WARM: On the Benefits of Weight Averaged Reward Models
In this WARM: On the Benefits of Weight Averaged Reward Models (Jan 22), researchers propose a weight averaging approach for LLM reward models. (“Reward models” refer to those used in reinforcement learning with human feedback, RLHF, for alignment.)
What is weight averaging? Since weight averaging and model merging for LLMs seem to be the most interesting themes in 2024, I want to briefly introduce this topic before diving further into the WARM paper.
Understanding Model Merging and Weight Averaging
Model merging and weight averaging, while not new, are currently the most prominent methods, dominating Open LLM leaderboards. Let’s briefly discuss these two concepts. (I may write a more detailed article some time in the future.)
Both weight averaging and model merging involve combining multiple models or checkpoints into a single entity. What are the advantages? Similar to the concept of creating model ensembles, this approach of combining multiple models into one can enhance training convergence, improve overall performance, and increase robustness. It’s worth highlighting that unlike traditional ensemble methods, model merging and weight averaging result in a singular model rather than maintaining multiple separate models, as illustrated in the figure below.
Traditionally, weight averaging involves averaging a single model’s weights (parameters) at different points in its training process. Typically, it’s done towards the end of the training when the model has nearly converged. A common form of this technique is Stochastic Weight Averaging (SWA), where we decay an initially large learning rate, and weights are averaged over several iterations during periods of decayed (but still relatively high) learning rates.
Since a model’s training trajectory can be uneven, the strategy is to average the models towards the end of the training when the learning rate is low (if a scheduler is used), as illustrated in the figure above, where the training is nearing convergence.
Alternatively, the Exponentially Moving Average (EMA) method, computes a smoothed version of the weights by exponentially decreasing the weights of older states.
In 2022, Latest Weight Averaging (LaWA) demonstrated that averaging the weights of the latest k checkpoints, each taken at the end of an epoch, can expedite training progress in terms of loss and accuracy by several epochs. This was shown to be effective for ResNet vision models and RoBERTa language models.
Then, in 2023, Early Weight Averaging Meets High Learning Rates for LLM Pre-training explored a modified version of LaWA with higher learning rates and an earlier start in averaging checkpoints during training. The researchers found that this approach significantly outperformed standard SWA and EMA techniques.
While weight averaging combines multiple checkpoints of the same model into a single model, model merging involves combining multiple different trained models into a single model. Each of these models may have been trained independently, possibly on different datasets or tasks.
Model merging goes back a long way, but the perhaps most recent and influential paper relevant to LLMs is Model Ratatouille: Recycling Diverse Models for Out-of-Distribution Generalization (thanks to Alexandre Ramé for drawing my attention to this).
The idea behind Model Ratatouille is to reuse multiple fine-tuned iterations of the identical base model across various diverse auxiliary tasks, as illustrated in the figure below.
To provide a bit more detail, the Model Ratatouille method can be summarized as shown in the figure below.
Note that this overall merging idea can also be applied to LoRA adapters, as shown in LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition.
I am planning to write more about model merging in the future. In the meantime, I can warmly recommend the reading list by Omar Sanseviero and ‘s article on model merging.
Weight Averaged Reward Models
Having discussed the concepts of weight averaging and model merging, let’s briefly go back to the newly released paper WARM: On the Benefits of Weight Averaged Reward Models, published on January 22nd last week.
This research primarily aims to enhance the RLHF alignment step for LLMs (RLHF is the method behind ChatGPT and Llama 2 Chat; for additional details on this process, please refer to my article LLM Training: RLHF and Its Alternatives). Specifically, the researchers attempt to mitigate reward hacking in LLMs by averaging the weights of finetuned reward models.
Reward hacking occurs when an LLM learns to manipulate or exploit its reward system’s flaws to attain high scores or rewards, without genuinely fulfilling the intended task or achieving the essential objectives.
To address reward hacking, the researchers suggest combining LLM reward models through weight averaging. The merged reward model resulting from this process attained a 79.4% win rate over a single reward model.
How does WARM function? The method is fairly straightforward: similar to stochastic weight averaging, WARM averages the weights of multiple models (in this case, reward models), as depicted in the figure below.
Previously, we discussed several weight averaging methods. How exactly does WARM average the weights to obtain the reward model? Here, they use a simple linear average as in stochastic weight averaging. The difference, however, is that the models are not sampled from the same trajectory but are independently created from the pretrained model, as in Model ratatouille. Alternatively WARM also has a so-called Baklava procedure to sample along a finetuning trajectory. The differences are compared in the figure below.
Following the WARM procedure above and averaging 10 reward models, the researchers found that an RL policy WARM has a 79.4% win rate against a policy with a single reward model, as shown in the figure below.
Conclusion
Model merging is not a new technique, but it seems that in the context of LLMs, it’s particularly promising since LLMs are very expensive and resource-intensive. Hence, methods that take advantage of multiple existing LLMs created during training (without extra work) are particularly attractive. Also, in contrast to traditional ensembles that require running multiple models at the same time, weight-averaged models are relatively lightweight and don’t cost more than a single model during inference time.
Looking ahead, I think that the future of model merging in LLMs holds exciting prospects. In particular, I also expect more creative ways of merging models on the horizon.
2. Tuning Language Models by Proxy
The paper Tuning Language Models by Proxy introduces a promising technique for improving Large Language Models (LLMs) called proxy-tuning. This method (sort of) finetunes LLMs without altering their weights.
Proxy-tuning works through a straightforward process at the decoding stage by adjusting the logits of the target LLM. Specifically, it involves calculating the difference in logits between a smaller base model and a finetuned model. This difference is then added to the logits of the target model. (Logits are the raw output values generated by the model’s final layer. Before being transformed into probabilities through a function like softmax, these logits represent the unnormalized scores for each possible output token in the LLMs vocabulary.)
To illustrate this concept more clearly, consider the objective of improving a large target model, M1 (for example, Llama 2 70B). The process involves two smaller models:
A small base model (M2) like Llama 2 7B
A finetuned version of the base model (M3) Llama 2 7B Chat
The enhancement is achieved by applying the difference in predictions (logits) of these smaller models to the target model M1. The output logits of the improved target model, M1*, is computed as M1*(x) = M1(x) + [M3(x) – M2(x)]. After obtaining these output logits, they are converted into probabilities using the softmax function. These probabilities are then used to sample the final output, i.e., the generated text, using nucleus sampling or top-k decoding.
How well does proxy-tuning work in practice?
The experimental results are impressively positive. The researchers applied their methods in three distinct scenarios:
Instruction-Tuning: Improve the 70B size Llama 2 Base mode to match the performance of the Llama 2 70B Chat model.
Domain Adaptation: Upgrading the 70B size Llama 2 Base model in coding tasks, aiming to reach the performance level of CodeLlama 70B.
Task-Specific Finetuning: Improving the 70B size Llama 2 Base model for specialized tasks such as TriviaQA or math problems.
In each scenario, significant improvements were observed compared to the original base models. The table below focuses on the comparison between the Llama 70B Base and Chat models for conciseness. However, the paper provides additional benchmarks for CodeLlama.
As one can see, based on the benchmarks shown in the figure above, the proxy-tuned 70B Llama 2 model performs much better than the 70B base model, and it’s almost as good as the directly tuned Llama 70B Chat model.
Practical Considerations
The use-case or motivation for using this method could be increasing R&D efficiency: developing new training or model enhancements and testing them on smaller models to reduce costs. Then, these methods can be scaled up to enhance larger base models without having to train large models.
However, implementing this approach in a real-world setting still involves using three different models:
A large general-purpose base model;
A smaller general-purpose model;
Several small specialized models tailored to specific use cases or client needs.
So, why choose this approach over LoRA (Low-Rank Adaptation), which doesn’t require the smaller general-purpose model (2) and can substitute multiple small specialized models (3) with a set of small LoRA matrices?
There are two potential advantages to the proxy-tuning approach:
a) It might outperform LoRA in certain contexts, although there’s no direct comparison available yet.
b) It’s useful when the large base model (1) is a “black box”, and its internal weights are inaccessible.
However, there’s a catch: the smaller models must share the same vocabulary as the larger target model. (In theory, if someone knows the vocabulary of GPT-4 and can access its logit outputs, they could create specialized GPT-4 models using this method.)
3. Mixtral of Experts
The Mixtral 8x7B paper is finally here! Mixtral 8x7B is a sparse mixture of experts (sparse MoE) model that currently ranks as one of the best performing and most interesting openly available large language models (LLMs). The model repository is released under an Apache 2 license and, according to the paper, is free to use for both academic and commercial purposes.
What is an MoE? An MoE, or Mixture of Experts, is a type of ensemble model that combines several smaller “expert” subnetworks. Each subnetwork is responsible for handling different types of tasks or, more concretely, tokens. By using multiple smaller subnetworks instead of one large network, MoEs aim to allocate computational resources more efficiently. This enables them to scale more effectively and potentially achieve better performance across a wider range of tasks. (Also see the brief Mixture of Experts 101 section in my previous article.)
In the Mixtral of Experts paper, which I’ll discuss below, the authors discuss how they built Mixtral 8x7B. This model compares very favorably to the much larger Llama 2 70B model.
Mixtral Architecture
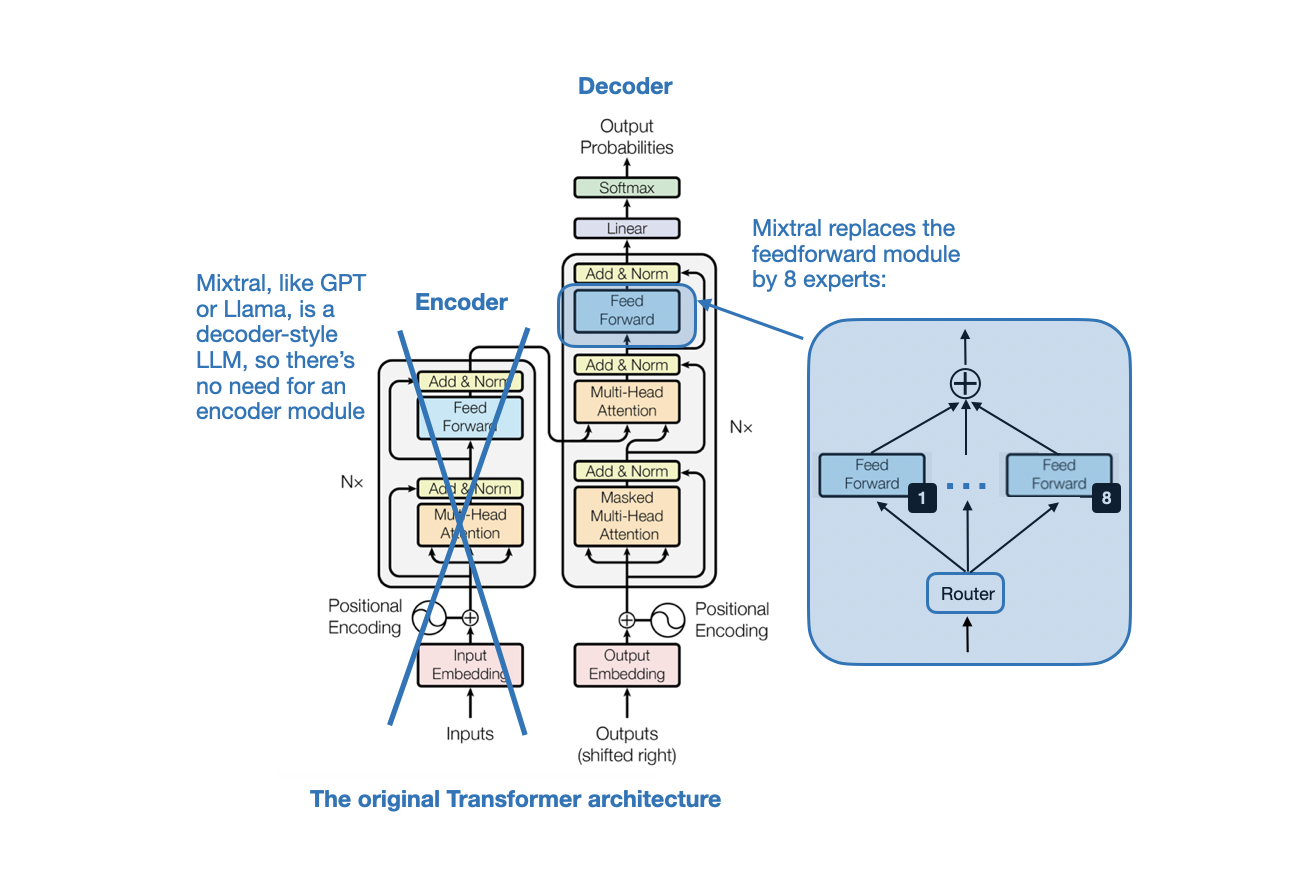
The key idea in Mixtral 8x7B is to replace each feed-forward module in a transformer architecture with 8 expert layers, as illustrated in the figure below.
A feed-forward module is essentially a multilayer perceptron. In PyTorch-like pseudocode, it essentially looks like this:
class FeedForward(torch.nn.Module):
def __init__(self, embed_dim, coef):
super().__init__()
self.layers = nn.Sequential(
torch.nn.Linear(embed_dim, coef*embed_dim),
torch.nn.ReLU(),
torch.nn.Linear(coef*n_embed, embed_dim),
torch.nn.Dropout(dropout)
)
def forward(self, x):
return self.layers(x)
In addition, there is a routing module (also known as a gating network) that redirects each of the token embeddings to the 8 expert feed-forward modules. The outputs from these 8 expert feed-forward layers are then summed, as illustrated in the figure below.
Mathematically, the figure above can be written as follows for the 8 experts {E1, E2, …, E8}:
Here, G represents the router (or gating network), and Ei are the outputs of the expert modules. Based on the equation above, the MoE layer computes a weighted sum of the expert outputs Ei, where the weights are provided by the gating network G(x)i for the inputs x.
At first glance, it might seem like Mixtral is simply adding additional parameters to an LLM via these expert (feed-forward) modules to represent a sort of weighted ensemble approach. However, there’s an additional tweak: Mixtral is a sparse MoE, which means that only a subset of the experts are used for each input:
In the specific case of Mixtral 8x7B, the authors specify TopK=2, meaning that only 2 experts are used at a time. So, based on the equation above, an output from G(x) might look as follows: [0, 0, 0.63, 0, 0, 0.37, 0, 0]. This indicates that the third expert contributes 63% to the output, and the sixth expert contributes 37%, respectively.
Model Size
Where does Mixtral 8x7B get its name, and what is the actual size of this sparse MoE model? The “8x” refers to the use of 8 expert subnetworks. The “7B” indicates that it combines Mistral 7B modules. However, it’s important to note that the size of Mixtral is not 8x7B = 56B. The 7 billion parameters represent the size of an entire Mistral 7B model, but in Mixtral 8x7B, only the feed-forward layers are replaced by expert layers.
In total, Mixtral 8x7B comprises 47B parameters. If we consider the following equations, where FF stands for the forward layers and NonFF refers to the non-feed forward layers (for instance, attention weights):
NonFF + 8*FF = 47B (MoE Mixtral model)
NonFF + FF = 7B (regular Mistral model)
Solving these equations, we find that the 7B mistral model has 40/7 = 5.71B parameters in the feed forward layers and 7B-5.71B = 1.29B parameters in the attention layers. Intriguingly, most of the parameters in an LLM are contained in a feed-forward module, not in the attention mechanism. And this is especially true for the Mixtral 8x7B model, which has 8*5.71B = 45.68B of its parameters in the expert (feed forward) layers.
With 47B parameters in total, Mixtral 8x7B is significantly smaller than, for example, the Llama 2 70B model. Moreover, since only 2 experts are active at each time step, the model utilizes only 13B parameters for each input token, making it much more efficient than a regular non-MoE 47B parameter model.
Expert Specialization
The interesting question is whether the experts exhibit any task- or token-specific patterns. Unfortunately, the authors were unable to observe such specialization by topic (where “topics” refer to datasets like GitHub, Arxiv, Mathematics, Wikipedia, etc.).
However, the authors make an interesting observation: consecutive tokens in text datasets are often assigned to the same experts. Additionally, indentation tokens in Python code are frequently assigned to the same expert, as shown in the figure below.
(The authors didn’t specify which of the two experts per token is colored, but I assume they always colored the expert with the higher weight.)
Conclusion
Mixtral 8x7B has several advantages: it’s openly available, matches or outperforms larger models such as Llama 2 70B, and employs sparse MoE modules in a relatively fresh (although not entirely new) way of building LLMs.
Its strong performance, coupled with parameter efficiency and the ability to handle context windows of up to 32k, will likely make it an attractive model for the foreseeable future (or, at least the upcoming months). I believe that MoE models will also be one of the main focus areas for most open-source projects in 2024, making Mixtral of Experts worth keeping on your radar.
If there’s one small nitpick, it’s that the authors did not share any information about the training datasets. (This may be understandable to avoid copyright debates.)
Furthermore, even though such a study would be very expensive, it would be intriguing to see how a Mixtral 8x70B would compare to a Llama 2 70B model trained on the same dataset. Furthermore, I’d be interested in seeing a comparison of Mixtral 8x70B with the following two hypothetical models some time in the future to more directly compare the performance of MoE and non-MoE approaches:
Mistral 56B (a larger non-MoE model)
Mistral 47B (a non-MoE model with the same number of parameters as Mixtral 8x70B)
(Fun fact: The Brave browser now uses Mixtral 8x7B as default LLM for their Leo assistant feature.)
4. TinyLlama: An Open-Source Small Language Model
After Microsoft’s phi-2 made headlines in December, TinyLlama is the latest addition to the “small” LLM category. TinyLlama is not only small, with 1.1 billion parameters, but also fully open source. Here, “open source” means that the training code and model checkpoints are available via an unrestricted open source library. You can find the GitHub repository here: https://github.com/jzhang38/TinyLlama.
What makes small LLMs (also referred to as SLMs, short for Small Language Models) so attractive? Small LLMs are:
Accessible and affordable, meaning they can be run (in inference mode) on limited resource regimes (such as laptops and/or small GPUs).
Cheaper to develop and pretrain — these models only require a relatively small number of GPUs.
Easier to customize for target tasks — small models can typically be finetuned on just a single GPU.
More energy-efficient — this is an important consideration given concerns about the environmental impact of training and running large-scale AI models. Or, think of battery life when deploying LLMs on portable devices such as smartphones.
Valuable for educational purposes — they are more manageable and thus easier to understand and tweak.
TinyLlama Performance
Besides being small and open-source, TinyLlama also performs relatively well on both common-sense reasoning and problem-solving benchmarks, compared to other open-source models of similar size.
Of course, TinyLlama can’t rival much larger models in those benchmarks, but since all the code is open source, it presents interesting opportunities for further studies and finetuning.
TinyLlama Learnings
For instance, an intriguing educational takeaway from the authors’ training runs is that training the model for 3 epochs (instead of 1 epoch) on 1 trillion tokens is actually beneficial (although maybe not optimal according to the Chinchilla scaling laws via Hoffmann et al., 2022).
For instance, as shown in the plot below, the model still keeps improving even though the data is repeated by training over multiple epochs.
Studying the behavior on “too large” datasets or running the training for more than one epoch would not be trivial with larger models. In any case, I am excited to see what future finetuning experiments on TinyLlama will yield. (Although, early experiments showed that it’s currently lacking behind the small but 3x larger phi-2 model.)
Other Interesting Research Papers In January
Below is a selection of other interesting papers I stumbled upon this month. Given the length of the list, I have highlighted those I found particularly interesting with an asterisk (*).
*KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization by Hooper, Kim, Mohammadzadeh, Mahoney, et al. (31 Jan), https://arxiv.org/abs/2401.18079
Researcher propose a method for quantizing key-value cache activations that achieves minimal perplexity degradation and enables the serving of models like Llama-7B with a context length of up to 1 million on a single A100 (80GB) GPU.
*Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling by Maini, Seto, Bai, Grangier, et al. (29 Jan), https://arxiv.org/abs/2401.16380
The authors propose using paraphrased web documents for training large language models more efficiently, resulting in faster pretraining, better performance on various tasks, and insights into how training data composition affects out-of-distribution performance.
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models by Lin, Tang, Ye, Cui, et al. (29 Jan), https://arxiv.org/abs/2401.15947
This paper proposes a mixture-of-experts paradigm to scale large vision-language models that achieves comparable performance to larger models with fewer parameters.
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty by Li, Wei, C. Zhang, and H. Zhang (26 Jan), https://arxiv.org/abs/2401.15077
EAGLE accelerates auto-regressive decoding in LLMs by processing at a secondary feature level and incorporating future tokens.
Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities by Zhang, Ding, Gong, Ge, and Yue (25 Jan), https://arxiv.org/abs/2401.14405
The paper introduces Multimodal Pathway, a technique to boost vision transformers for a specific modality (like images) by using unpaired data from different modalities (like audio) resulting in significant performance improvements in various image recognition tasks.
Pix2gestalt: Amodal Segmentation by Synthesizing Wholes by Ozguroglu, Liu, Surís, Chen, et al. (25 Jan), https://arxiv.org/abs/2401.14398
Pix2gestalt is a framework for zero-shot amodal image segmentation that utilizes diffusion models and a synthetically curated dataset to estimate the shape and appearance of partially occluded objects.
Rethinking Patch Dependence for Masked Autoencoders by Fu, Lian, Wang, Shi, at al. (25 Jan), https://arxiv.org/abs/2401.14391
Cross-Attention Masked Autoencoders is a novel pretraining framework that uses only cross-attention between masked and visible tokens for masked patch reconstruction, which improves both efficiency and quality over traditional masked autoencoders.
SpacTor-T5: Pre-training T5 Models with Span Corruption and Replaced Token Detection by Ye, Jiang, Rostamizadeh, Chakrabarti, et al. (24 Jan), https://arxiv.org/abs/2401.13160
This paper introduces SPACTOR, a training method for LLMs that combines span corruption1 and token replacement detection2 in a two-stage curriculum, achieving the same performance as standard methods with 50% fewer pre-training iterations and 40% less computational cost.
1 Instead of masking individual tokens like in BERT, T5 randomly replaces contiguous spans of tokens in the input text with a single mask token.
2 In replacement detection, some tokens (words or subwords) in the input text are replaced with other tokens, and the model’s task is to identify which tokens have been replaced.
MambaByte: Token-free Selective State Space Model by Wang, Gangavarapu, Yan, and Rush (24 Jan), https://arxiv.org/abs/2401.13660
MambaByte is a token-free language Mamba selective state space model that operates on raw bytes to avoid subword tokenization bias.
Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text by Hans, Schwarzschild, Cherepanova, Kazemi, et al. (22 Jan), https://arxiv.org/abs/2401.12070
Binoculars is a new, (more) accurate method for detecting text generated by LLMs without training data, using simple calculations contrasting two pre-trained LLMs.
*WARM: On the Benefits of Weight Averaged Reward Models by Ramé, Vieillard, Hussenot, Dadashi, et al. (22 Jan), https://arxiv.org/abs/2401.12187
This study addresses reward collapse in LLMs aligned with human preferences through reinforcement learning by averaging finetuned reward model weights.
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities by Chen, Xu, Kirmani, Ichter, et al. (22 Jan), https://arxiv.org/abs/2401.12168
This research improves Vision Language Models (VLMs) in 3D spatial reasoning by developing an internet-scale spatial reasoning dataset and training a VLM on it.
*Knowledge Fusion of Large Language Models by Wan, Huang, Cai, Quan, et al. (19 Jan), https://arxiv.org/abs/2401.10491
The researchers propose a knowledge fusion method that combined multiple diverse LLMs into a unified model, which outperforms individual models, traditional ensembles, and other model merging methods.
VMamba: Visual State Space Model by Liu, Tian, Zhao, Yu, et al. (18 Jan), https://arxiv.org/abs/2401.10166
This research combines the global receptive fields and dynamic weights of Vision Transformers with the linear complexity of CNNs into a new architecture called VMamba, which performs particularly well at higher image resolutions.
* Self-Rewarding Language Models by Yuan, Pang, Cho, Sukhbaatar, et al. (18 Jan), https://arxiv.org/abs/2401.10020
Employing the LLM-as-a-Judge method for self-rewarding during training, researchers were able to improve LLM capabilities in following instructions and modeling rewards, which indicates the possibility for ongoing self-enhancement beyond the usual training based on human preferences.
DiffusionGPT: LLM-Driven Text-to-Image Generation System by Qin, Wu, Chen, Ren, et al. (18 Jan), https://arxiv.org/abs/2401.10061
DiffusionGPT is a text-to-image generation framework that uses LLMs to parse diverse prompts and select the most suitable generative model from a Tree-of-Thought structure that also integrates human feedback.
ReFT: Reasoning with Reinforced Fine-Tuning by Luong, Zhang, Jie, Sun, et al. (17 Jan), https://arxiv.org/abs/2401.08967
The paper presents Reinforced FineTuning (ReFT), a technique that improves the reasoning abilities of Large Language Models in tasks like math problem-solving by combining supervised finetuning with reinforcement learning, achieving improved results over standard finetuning without extra training data.
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture by Balaguer, Benara, de Freitas Cunha, Estevão Filho, et al. (16 Jan), https://arxiv.org/abs/2401.08406
While there’s usually a “Retrieval-Augmented Generation (RAG) vs. Finetuning” debate, this paper demonstrates that combining RAG and finetuning results in cumulative accuracy improvements (in the context of an agricultural application).
Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering by Ridnik, Kredo, and Friedman (Jan 16), https://arxiv.org/abs/2401.08500
AlphaCodium is an iterative, test-based approach for code generation in LLMs outperforming previous methods with a smaller computational budget.
* Scalable Pre-training of Large Autoregressive Image Models by El-Nouby, Klein, Zhai, Bautista, et al. (16 Jan), https://arxiv.org/abs/2401.08541
The paper pretrains vision models autoregressively (without supervision), inspired by LLM pretraining, demonstrating that their performance scales with model size and data quantity, and achieves notable results on ImageNet-1k without saturation.
* Tuning Language Models by Proxy by Liu, Han, Wang et al. (16 Jan), https://arxiv.org/abs/2401.08565
Proxy-tuning is a resource-efficient method that adapts large language models by using a smaller tuned model to modify their predictions, achieving near-equivalent performance to direct tuning, even on proprietary models.
An Experimental Design Framework for Label-Efficient Supervised Finetuning of Large Language Models by Bhatt, Chen, Das et al. (12 Jan), https://arxiv.org/abs/2401.06692
Using experimental design techniques in supervised finetuning of LLMs, which select the most informative samples for labeling to maximize efficiency, researchers cut the annotation costs by 50% compared to random sampling.
A Closer Look at AUROC and AUPRC under Class Imbalance by McDermott, Hansen, Zhang, et al. (11 Jan), https://arxiv.org/abs/2401.06091
This paper challenges the widely-held belief in machine learning that the area under the precision-recall curve (AUPRC) is superior to the area under the receiver operating characteristic (AUROC) for class-imbalanced binary classification.
* The Unreasonable Effectiveness of Easy Training Data for Hard Tasks by Hase, Bansal, Clark, and Wiegreffe, https://arxiv.org/abs/2401.06751
The authors find that models often generalize well from easy to hard data, and suggest it’s more efficient to train on easier data, as demonstrated through experiments with models up to 70 billion parameters on diverse question-answering datasets.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training by Hubinger, Denison, Mu, et al. (10 Jan), https://arxiv.org/abs/2401.05566
This study investigates the possibility of LLMs learning deceptive behaviors, such as writing secure code for prompts indicating the year 2023 but inserting exploitable code for the year 2024, and discovers that standard safety training techniques are ineffective at removing these persistent, deceptive strategies.
Transformers are Multi-State RNNs by Oren, Hassid, Adi, and Schwartz (11 Jan), https://arxiv.org/abs/2401.06104
This study shows that decoder-only transformers, originally seen as distinct from recurrent neural networks (RNNs), can be understood as infinite multi-state RNNs with unlimited hidden state size.
RoSA: Accurate Parameter-Efficient Fine-Tuning via Robust Adaptation by Nikdan, Tabesh, and Alistarh (9 Jan), https://arxiv.org/abs/2401.04679
This research introduces Robust Adaptation (RoSA), a new parameter-efficient finetuning method for LLMs, which outperforms existing methods like LoRA by training low-rank and highly-sparse components on fixed pretrained weights.
A Minimaximalist Approach to Reinforcement Learning from Human Feedback by Swamy, Dann, Kidambi et al. (8 Jan), https://arxiv.org/abs/2401.04056
The paper introduces Self-Play Preference Optimization (SPO), a simple yet effective reinforcement learning algorithm as an alternative to reinforcement with human feedback (RLHF) but without needing a reward model.
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts by Pioro, Ciebiera, Krol et al. (8 Jan), https://arxiv.org/abs/2401.04081
The paper proposes combining state space models like Mamba with mixture of experts (MoE), resulting in the MoE-Mamba model that outperforms both the standard Mamba structured state space model and a Transformer-MoE baseline in efficiency and effectiveness.
* Mixtral of Experts by Jiang, Sablayrolles, Roux, et al. (8 Jan), https://arxiv.org/abs/2401.04088
Mixtral 8x7B is a sparse Mixture of Experts model that modifies Mistral 7B with 8 experts per layer, resulting in a 47B parameter model matching or outperforming larger models like Llama 2 70B in several benchmarks.
Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon by Zhang, Liu, Xiao, Shao, et al. (7 Jan 2024), https://arxiv.org/abs/2401.03462
Researchers suggest to extend the context window of LLMs via a so-called activation beacon, a compressed state of the activations that is added to the input context.
* Denoising Vision Transformers by Yang, Luo, Li et al. (5 Jan), https://arxiv.org/abs/2401.02957
The authors found that common grid-like artifacts in vision transformers (ViTs) are due to positional embeddings at the input stage, and they propose a denoising vision transformer that can extract cleaned features of existing ViTs.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism by Bi, Chen, Chen et al. (5 Jan), https://arxiv.org/abs/2401.02954
DeepSeek LLM, using 7B and 67B configurations and trained on a 2 trillion token dataset, refines the Chinchilla scaling laws and outperforms models like LLaMA-2 70B and GPT-3.5.
Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM by Lu, Liusie, Raina et al. (4 Jan) https://arxiv.org/abs/2401.02994
This paper introduces “Blending”, a method that stochastically selects responses from multiple smaller chat AI models, showing that a combination of moderate-sized models (6B/13B parameters) can achieve or even exceed the performance of larger models like ChatGPT (175B+ parameters)
LLM Augmented LLMs: Expanding Capabilities through Composition by Bansal, Samanta, Dalmia et al. (4 Jan), https://arxiv.org/abs/2401.02412
CALM (Composition to Augment Language Models) combines foundational and specialized LLMs using cross-attention to improve on new tasks (like translation and code generation for low-resource languages) with minimal additional parameters and data.
LLaMA Pro: Progressive LLaMA with Block Expansion by Wu, Gan, Ge et al. (4 Jan), https://arxiv.org/abs/2401.02415
The paper presents a post-pretraining method for LLMs (turning Llama 7B to Llama Pro-8.3B) that expands Transformer blocks to improve in areas such as programming and mathematics without forgetting previous knowledge.
A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity by Lee, Bai, Pres et al. (3 Jan), https://arxiv.org/abs/2401.01967
This study explores how the direct preference optimization (DPO) algorithm aligns pre-trained models like GPT2-medium to user preferences by reducing toxicity, revealing that it bypasses rather than removes pre-training capabilities, and also shows a method to revert the model to its original toxic behavior.
LLaMA Beyond English: An Empirical Study on Language Capability Transfer by Zhao, Zhang, Gao et al. (2 Jan), https://arxiv.org/abs/2401.01055
This paper investigates how to transfer the capabilities of LLMs like Llama to non-English languages — a comparable performance to state-of-the-art models can be achieved with less than 1% of the pretraining data.
* Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models by Chen, Deng, Yuan et al. (2 Jan), https://arxiv.org/abs/2401.01335
This paper introduces Self-Play fIne-tuNing (SPIN), a method that enhances LLMs without additional human-annotated data by using a self-play mechanism where the LLM generates and refines its training data.
LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning by Jin, Han, Yang, et al. (2 Jan), https://arxiv.org/abs/2401.01325
In this paper, the authors propose a simple (4 lines of code) technique to extend the context-handling capabilities of LLMs without any finetuning.
A Comprehensive Study of Knowledge Editing for Large Language Models (2 Jan), by Zhang, Yao, Tian et al. https://arxiv.org/abs/2401.01286
This paper discusses how to keep an LLM relevant and up-to-date by reviewing various knowledge editing techniques (resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge) along with a new KnowEdit benchmark.
Astraios: Parameter-Efficient Instruction Tuning Code Large Language Models (1 Jan), by Terry Zhuo, Zebaze, Suppattarachai et al., https://arxiv.org/abs/2401.00788
This paper evaluates different full- and parameter-efficient finetuning techniques and finds that full-finetuning usually leads to the best performance, and LoRA usually offers the most favorable trade-off between cost and performance.
Building a Large Language Model from Scratch
Creating an LLM from scratch is an excellent way to gain a deep understanding of its inner workings. In my book project, “Building a Large Language Model from Scratch,” I code and detail the entire process, from developing an LLM architecture to implementing pretraining, fine-tuning, and alignment steps.
For more information, please visit the GitHub repository at https://github.com/rasbt/LLMs-from-scratch.
This magazine is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.
Your support means a great deal! Thank you!